给开发者的提示工程实战手册
/ 84 min read
Table of Contents
程序员的提示工程实战手册
本文翻译自 Addy Osmani 的文章:The Prompt Engineering Playbook for Developers。
开发者越来越依赖 AI 编程助手来加速我们的日常工作流程。这些工具可以自动补全函数、建议错误修复,甚至生成整个模块或最小可行产品(MVP)。然而,正如我们许多人所了解到的,AI 输出的质量在很大程度上取决于你提供的提示的质量。换句话说,提示工程已成为一项至关重要的技能。一个措辞不佳的请求可能会产生不相关或泛泛的答案,而一个精心设计的提示则可以产出深思熟虑、准确甚至富有创意的代码解决方案。本文将从实践角度探讨如何系统地为常见的开发任务撰写有效的提示。
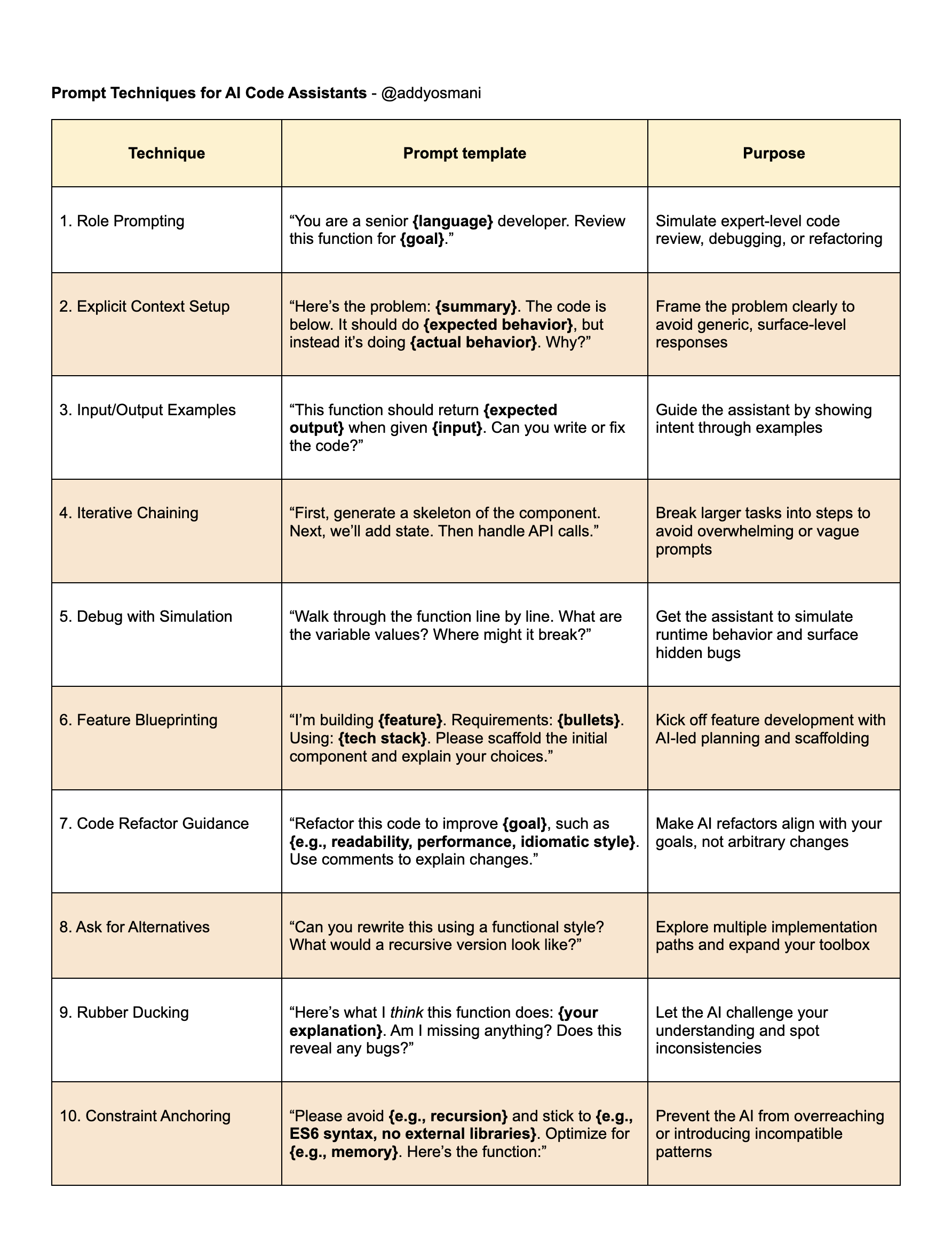
AI 结对程序员功能强大但并非魔法——除了你告诉它或作为上下文包含的信息外,它们对你的具体项目或意图一无所知。你提供的信息越多,输出就越好。我们将提炼出关键的提示模式、可复用的框架以及那些在开发者中引起共鸣的、令人印象深刻的示例。你将看到好提示与坏提示的并排比较及其真实的 AI 响应,并附有评论以理解为什么一个成功而另一个失败。这里有一份入门速查表:
向 AI 编程工具提问,有点像与一个非常较真、有时知识渊博的合作者沟通。为了获得有用的结果,你需要清晰地设定场景,并指导 AI 做什么以及如何做。
以下是支撑本手册所有示例的基础原则:
-
提供丰富的上下文。 始终假设 AI 对你的项目一无所知,除了你提供的信息。包括相关细节,如编程语言、框架和库,以及具体的函数或代码片段。如果出现错误,请提供确切的错误信息,并描述代码应该做什么。特异性和上下文是区分模糊建议和精确、可操作解决方案的关键。在实践中,这意味着你的提示可能包含一个简短的开场,例如:“我有一个使用 Express 和 Mongoose 的 Node.js 函数,它应该通过 ID 获取用户,但抛出了一个 TypeError。这是代码和错误信息……”。你给出的铺垫越多,AI 需要猜测的就越少。
-
明确你的目标或问题。 模糊的查询导致模糊的答案。与其问“为什么我的代码不工作?”,不如指出你需要什么洞见。例如:“这个 JavaScript 函数返回了 undefined 而不是预期的结果。根据下面的代码,你能帮我找出原因并修复它吗?” 这样更有可能得到有用的回答。一个用于调试的提示公式是:“预期它会做 [预期行为],但当输入 [示例输入] 时,它却做了 [当前行为]。bug 在哪里?” 同样,如果你想要优化,就要求进行特定类型的优化(例如,“我如何能提高这个排序函数处理 1 万个项目时的运行时性能?”)。特异性可以引导 AI 的注意力。
-
分解复杂任务。 在实现新功能或处理多步骤问题时,不要把整个问题塞进一个巨大的提示里。将工作分成更小的块并进行迭代通常更有效。例如,“首先,为产品列表页面生成一个 React 组件骨架。接下来,我们添加状态管理。然后,我们再集成 API 调用。” 每个提示都建立在前一个的基础上。通常不建议一次性要求完成一个大的功能;相反,应从一个高层次的目标开始,然后迭代地要求每个部分。这种方法不仅使 AI 的响应保持专注和可管理,也模仿了人类逐步构建解决方案的方式。
-
包含输入/输出或预期行为的示例。 如果你能用一个例子来说明你想要什么,那就这么做。例如,“给定数组 [3,1,4],这个函数应该返回 [1,3,4]。” 在提示中提供一个具体的例子有助于 AI 理解你的意图并减少歧义。这类似于给初级开发者一个快速的测试用例——它澄清了需求。在提示工程术语中,这有时被称为“少样本提示(few-shot prompting)”,即你向 AI 展示一个要遵循的模式。即使只有一个正确行为的例子,也能显著地引导模型的响应。
-
利用角色或身份(persona)。 一个在许多病毒式传播的提示示例中普及的强大技巧是,要求 AI “扮演”某个角色或身份。这可以影响答案的风格和深度。例如,“扮演一名资深的 React 开发者,审查我的代码中潜在的 bug” 或 “你是一名 JavaScript 性能专家。优化以下函数。” 通过设定一个角色,你引导助手采用相关的口吻——无论是作为一个严格的代码审查员,一个为初级开发者提供帮助的老师,还是一个寻找漏洞的安全分析师。社区分享的提示已经证明了这种方法的成功,例如*“扮演一个 JavaScript 错误处理专家,帮我调试这个函数。从 API 调用返回的数据没有正确渲染。”* 在我们自己的使用中,我们仍然需要提供代码和问题细节,但角色扮演提示可以产生更结构化和专家级的指导。

-
迭代和优化对话。 提示工程是一个交互式的过程,而不是一次性的交易。开发者通常需要审查 AI 的第一个答案,然后提出后续问题或进行修正。如果解决方案不完全正确,你可能会说,“那个解决方案使用了递归,但我更喜欢迭代的方法——你能再试一次,不用递归吗?” 或者,“很好,现在你能改进一下变量名并添加注释吗?” AI 会在聊天会话中记住上下文,所以你可以逐步引导它达到期望的结果。关键是把 AI 看作一个你可以指导的伙伴——追求进步而非第一次就完美。
-
保持代码的清晰度和一致性。 这最后一个原则有点间接,但对于那些需要处理你代码上下文的工具来说非常重要。即使在 AI 介入之前,也要编写清晰、结构良好的代码和注释。有意义的函数和变量名、一致的格式以及文档字符串不仅使你的代码更易于人类理解,也为 AI 提供了关于你正在做什么的更强有力的线索。如果你展示了一种一致的模式或风格,AI 会继续沿用它。把这些工具当作极其专注的初级开发者——它们会从你的代码和注释中获取每一个线索。
牢记这些基本原则,让我们深入探讨具体场景。我们将从调试开始,这可能是最直接的用例:你有一段行为不正常的代码,你希望 AI 帮助找出原因。
调试非常适合 AI 助手。这就像拥有一个不仅会倾听,还会用建议回应你的橡皮鸭。然而,成功与否很大程度上取决于你如何向 AI 呈现问题。以下是如何系统地为寻找和修复 bug 提问的方法:
1. 清晰地描述问题和症状。 在提示的开头,描述哪里出了问题以及代码应该做什么。始终包含确切的错误信息或不正确的行为。例如,不要只说“我的代码不工作”,你可以这样提问:“我有一个 JavaScript 函数,它应该计算一个数字数组的总和,但它返回的是 NaN (Not a Number),而不是实际的总和。这是代码:[包含代码]。对于像 [1,2,3] 这样的数字数组,它应该输出一个数字(总和),但我得到了 NaN。这个 bug 的原因可能是什么?” 这个提示指定了语言、预期行为、观察到的错误输出,并提供了代码上下文——所有这些都是至关重要的信息。提供一个结构化的上下文(代码 + 错误 + 预期结果 + 你尝试过的方法)能给 AI 一个坚实的起点。相比之下,像“为什么我的函数不工作?”这样的泛泛问题只会得到微不足道的结果——模型在没有上下文的情况下只能给出最笼统的猜测。
2. 对于棘手的 bug,使用逐步或逐行的方法。 对于更复杂的逻辑 bug(没有明显错误信息抛出,但输出错误),你可以提示 AI 逐行走查代码的执行过程。例如:“逐行执行这个函数,并跟踪每一步中 total 变量的值。它没有正确累加——逻辑错在哪里了?” 这是一个橡皮鸭调试提示的例子——你实际上是在要求 AI 模拟人类可能用打印语句或调试器进行的调试过程。这样的提示通常能揭示一些细微的问题,比如变量没有重置或条件逻辑不正确,因为 AI 会详细说明每一步的状态。如果你怀疑代码的某个特定部分,可以聚焦于此:“解释一下这里的 filter 调用在做什么,以及它是否可能排除了比预期更多的项目。” 让 AI 扮演解释者的角色,可以在解释的过程中发现 bug。
3. 尽可能提供最小可复现示例。 有时你的实际代码库很大,但 bug 可以在一小段代码中复现。如果你能提取或简化那段仍然能复现问题的代码,就这么做,并把它提供给 AI。这不仅让 AI 更容易聚焦,也迫使你澄清问题(这本身通常就是一个有用的练习)。例如,如果你在一个深层嵌套的函数调用中遇到了 TypeError,试着用几行代码来复现它并分享。目标是用最少的代码隔离 bug,对问题所在做出假设,进行测试,然后迭代。你可以让 AI 参与这个过程,说:“这是一个仍然能触发错误的精简示例 [包含代码片段]。为什么会发生这个错误?” 通过简化,你消除了噪音,帮助 AI 精准定位问题。(这个技巧呼应了许多资深工程师的建议:如果不能立即找到 bug,就简化问题空间。如果你向 AI 展示一个更小的情景,它可以协助你进行分析。)
4. 提出有针对性的问题和后续追问。 提供上下文后,直接询问你需要什么通常很有效,例如:“可能是什么导致了这个问题,我该如何修复它?”。这会邀请 AI 同时进行诊断和提出解决方案。如果 AI 的第一个回答不清楚或只有部分帮助,不要犹豫,提出后续问题。你可以说,“那个解释说得通。你能向我展示如何修复代码吗?请提供修正后的代码。” 在聊天环境中,AI 有对话历史,所以它可以直接输出修改后的代码。如果你在 VS Code 或 Cursor 中使用像 Copilot 这样的内联工具而没有聊天功能,你可以在代码上方写一条注释,比如 // BUG: returns NaN, fix this function,然后看它如何自动补全——但总的来说,交互式聊天能提供更详尽的解释。另一个后续追问的模式是:如果 AI 给出了一个修复方案但你不明白为什么,可以问*“你能解释一下为什么那个改动能解决问题吗?”* 这样你下次就能学到东西,并且可以再次确认 AI 的推理是否合理。
现在,让我们用一个具体的例子来说明这些调试提示原则,展示一个差的提示 vs. 改进的提示以及 AI 响应的差异:
假设我们有一个简单的 Node.js 函数,旨在将一个用户对象列表转换为一个按用户 ID 查找的映射。然而,它抛出了一个错误。这是有问题的代码:
// 有问题的函数:将用户数组转换为按 ID 索引的 mapfunction mapUsersById(users) { const userMap = {}; for (let i = 0; i <= users.length; i++) { // 注意:使用 <= 将在最后一次迭代时越界 const user = users[i]; userMap[user.id] = user; } return userMap;}
// 示例用法:const result = mapUsersById([{ id: 1, name: "Alice" }]);这段代码本应遍历 users 数组并构建一个以用户 ID 为键的对象。然而,这里有一个 bug:循环使用了 i <= users.length 而不是 i < users.length。这将导致在最后一次迭代中 users[i] 为 undefined,很可能导致运行时错误(例如,尝试访问 undefined 的 id 属性)。让我们看看 AI 助手对关于这个问题的两个不同提示会如何回应。
❌ 差的提示: “为什么我的 mapUsersById 函数不工作?”
AI 对差提示的响应(模拟):
没有更多信息很难说。你确定这个函数被调用时传入了正确的用户数组吗?问题可能在于
users是空的或不是一个数组,导致循环没有正确执行。也可能是在userMap上设置属性时出错。请确保每个用户都有一个id属性。如果users是undefined或null,也会导致它不工作。
分析: 这个回答非常模糊。提示除了函数名外没有提供任何细节,所以 AI 只能猜测一些常见原因(“也许数组是空的或不是数组”,“确保每个用户都有一个 id 属性”)。它没有识别出真正的 bug。当你提问不够具体时,就会得到这种响应——模型只能复述一些常见的调试技巧。作为一个开发者,这没什么帮助,因为它没有解决真正的问题。提示中缺乏上下文和特异性导致了一个泛泛的答案(基本上是 AI 版的“你试过重启吗?”)。这与社区的建议一致,即模糊的提示会导致不相关或泛泛的答案。
✅ 改进的提示: “我有一个 JavaScript 函数 mapUsersById,它应该将一个用户对象数组转换为一个以用户 ID 为键的映射(对象)。然而,当我运行它时,它抛出了一个错误。例如,当我传入 [ {id: 1, name: "Alice"} ] 时,我得到 TypeError: Cannot read property 'id' of undefined。这是函数代码:
function mapUsersById(users) { const userMap = {}; for (let i = 0; i <= users.length; i++) { const user = users[i]; userMap[user.id] = user; } return userMap;}它应该返回 { "1": {id: 1, name: "Alice"} }。bug 是什么,我该如何修复它?”
AI 对改进提示的响应(模拟):
TypeError: Cannot read property 'id' of undefined这个错误表明,在某个时刻user变量是undefined,然后你试图访问user.id。查看你的循环,问题出在循环的边界条件上。你使用了i <= users.length。如果users.length是 1(数组中有一个用户),循环会以 i = 0 和 i = 1 运行。当 i 为 1 时,users[1]是undefined(因为数组中唯一的索引是 0)。因此,在那次迭代中user变成了undefined,访问user.id就会抛出TypeError。修复方法是将循环条件改为i < users.length,这样 i 的范围就是从 0 到users.length-1。例如:
for (let i = 0; i < users.length; i++) { const user = users[i]; userMap[user.id] = user;}这样,对于第一个(也是唯一的)元素,i 将为 0,然后循环停止。做了这个改动后,你的函数将不再遇到
undefined的用户,并且应该能按预期工作,对于给定的输入返回{"1": {id: 1, name: "Alice"}}。
分析: 这个响应直接指出了 bug(在循环中使用了 <=),并解释了为什么它导致 user 变为 undefined。然后,它提供了正确的代码解决方案(i < users.length)并确认了预期的结果。改进的提示之所以成功,是因为它遵循了我们的原则:它指定了语言(JavaScript),描述了函数的功能,包含了确切的错误信息和示例输入,甚至提供了相关的代码片段。注意 AI 是如何利用错误信息作为线索,将注意力集中在循环边界上的——一个有针对性的提示使得 AI 能够进行真正的问题解决,有效地模拟了人类调试者的思维过程:“undefined 可能从哪里来?很可能是循环索引的问题”。这是一个具体展示详细提示好处的例子。
额外的调试策略: 除了识别明显的 bug,你还可以使用提示工程来获得更深层次的调试帮助:
-
询问可能的原因。 如果你真的毫无头绪,可以稍微扩大问题的范围:“在这段代码中,出现
TypeError: cannot read property 'foo' of undefined的可能原因有哪些?” 并附上代码。模型可能会列出几种情况(例如,对象未初始化、竞态条件、变量作用域错误等)。这可以为你提供一些你未曾考虑过的调查方向。这就像与同事进行头脑风暴。 -
“请教橡皮鸭” —— 即,向 AI 解释你的代码。这听起来可能有些反直觉(为什么要向助手解释?),但撰写解释的过程可以澄清你自己的理解,然后你可以让 AI 来验证或批评它。例如:“我来解释一下这个函数在做什么:[你的解释]。基于此,我的推理是否正确?它是否揭示了 bug 所在?” AI 可能会在你的解释中发现一个指向实际 bug 的缺陷。这个技巧利用 AI 作为一个积极的橡皮鸭,它不仅倾听,还会回应。
-
让 AI 创建测试用例。 你可以问:“你能提供几个可能会破坏这个函数的测试用例(输入)吗?” 助手可能会想出你没有想到的边缘情况(空数组、极大数值、
null值等)。这对于调试和为未来的健壮性生成测试都很有用。 -
扮演代码审查员。 作为直接“调试这个”提示的替代方案,你可以说:“扮演一个代码审查员。这里有一段代码片段没有按预期工作。请审查它,并指出任何可能导致问题的错误或不良实践:[代码]”。这将使 AI 进入一种批判模式。许多开发者发现,将请求表述为代码审查会得到非常详尽的分析,因为模型会评论代码的每个部分(并且通常在这样做时,它会发现 bug)。事实上,一个提示工程的技巧是明确要求 AI 表现得像一个细致的审查员。这不仅能发现手头的 bug,还能发现其他问题(例如,可能缺少
null检查),这可能很有用。
总之,当使用 AI 助手进行调试时,细节和方向是你的朋友。提供场景、症状,然后提出有针对性的问题。正如我们上面所看到的,一个含糊的“它不工作,帮帮我!”提示和一个精准的调试提示之间有天壤之别。接下来,我们将转向另一个主要用例:重构和改进现有代码。
重构代码——在不改变其功能的前提下,使其更清晰、更快或更符合语言习惯——是 AI 助手可以大放异彩的领域。它们在海量代码上进行过训练,其中包括许多结构良好、经过优化的解决方案示例。然而,要有效地利用这些知识,你的提示必须阐明在你的情境下“更好”意味着什么。以下是如何为重构任务提问的方法:
1. 明确陈述你的重构目标。 单纯的“重构这段代码”太开放了。你是想提高可读性?降低复杂度?优化性能?还是使用不同的范式或库?AI 需要一个目标。一个好的提示会框定任务,例如:“重构以下函数以提高其可读性和可维护性(减少重复、使用更清晰的变量名)。” 或者 “优化这个算法的速度——它在处理大输入时太慢了。” 通过陈述具体目标,你帮助模型决定应用哪些转换。例如,告诉它你关心性能可能会让它使用更高效的排序算法或缓存,而专注于可读性则可能让它将一个函数分解成更小的函数或添加注释。如果你有多个目标,请一一列出。Strapi 指南中的一个提示模板甚至建议列举问题:“我希望解决的问题:1) [性能问题],2) [代码重复],3) [过时的 API 用法]。” 这样,AI 就确切地知道要修复什么。记住,它不会天生知道你认为代码中有什么问题——你必须告诉它。
2. 提供必要的代码上下文。 重构时,你通常会在提示中包含需要改进的代码片段。重要的是要包含你想要重构的完整函数或部分,有时如果相关的话,还包括一些周围的上下文(比如函数的用法或相关代码,这可能会影响你如何重构)。同时也要提及语言和框架,因为“地道”的代码在不同环境中是不同的,比如地道的 Node.js 与地道的 Deno,或者 React 类组件与函数式组件。例如:“我有一个用类编写的 React 组件。请将其重构为使用 Hooks 的函数式组件。” AI 随即便会应用典型的步骤(使用 useState、useEffect 等)。如果你只是说“重构这个 React 组件”而没有阐明风格,AI 可能不知道你特指想要用 Hooks。
- 如果相关,请包含版本或环境细节。 例如,“这是一个 Node.js v14 的代码库” 或 “我们正在使用 ES6 模块”。这会影响 AI 是否使用某些语法(如
import/exportvs.require),这是正确重构的一部分。如果你想确保它不会引入不兼容的东西,请提及你的约束。
3. 鼓励代码和解释一并提供。 从 AI 主导的重构中学习(并验证其正确性)的一个好方法是要求对更改进行解释。例如:“请建议一个重构后的代码版本,并解释你所做的改进。” 这甚至被我们引用的提示模板所包含:“……建议重构后的代码,并对你的更改做出解释。” 当 AI 提供了解释,你就可以评估它是否理解了代码并达到了你的目标。解释可能会说:“我将两个相似的循环合并成一个以减少重复,并使用了字典以加快查找速度,”等等。如果解释中有什么听起来不对劲,那就是一个仔细检查代码的警示信号。简而言之,利用 AI 的解释能力作为一种保障——这就像让 AI 对自己的重构进行代码审查。
4. 使用角色扮演来设定高标准。 如前所述,要求 AI 扮演代码审查员或资深工程师的角色可能非常有效。对于重构,你可能会说:“扮演一位经验丰富的 TypeScript 专家,重构这段代码,使其符合最佳实践和现代标准。” 这通常不仅会产生表面的改变,还会带来更有洞察力的改进,因为 AI 会努力达到“专家”的身份。一个来自提示指南的流行例子是让 AI 扮演导师的角色:“扮演一位经验丰富的 Python 开发者,指导一名初级开发者。提供解释并编写文档字符串。重写代码以进行优化。” 在那个案例中,结果是 AI 使用了更高效的数据结构(用 set 去重)并为一个原本使用循环的函数提供了一行解决方案。角色扮演不仅帮助它重构,还解释了为什么新方法更好(在该案例中,使用 set 是一个众所周知的用于保证唯一性的优化)。
现在,让我们通过一个重构的例子,看看提示如何影响结果。我们将使用一个 JavaScript (Node.js) 的场景,我们有一些不太理想的代码,希望对其进行改进。
假设我们有一个函数,它进行两次数据库调用并做一些处理。它能工作,但不够美观——有重复的代码,而且难以阅读。我们希望为了清晰度和效率对其进行重构。这是原始代码:
// 原始函数:获取两个列表并处理它们(需要重构)async function getCombinedData(apiClient) { // 获取用户列表 const usersResponse = await apiClient.fetch("/users"); if (!usersResponse.ok) { throw new Error("获取用户失败"); } const users = await usersResponse.json(); // 获取订单列表 const ordersResponse = await apiClient.fetch("/orders"); if (!ordersResponse.ok) { throw new Error("获取订单失败"); } const orders = await ordersResponse.json(); // 合并数据(将用户与订单匹配) const result = []; for (let user of users) { const userOrders = orders.filter((o) => o.userId === user.id); result.push({ user, orders: userOrders }); } return result;}这段代码的问题:我们看到用户和订单的获取逻辑是重复的(可以重构为一个辅助函数或循环),错误信息缺乏细节(只是一个通用的错误消息),而且它或许可以并行执行获取操作以提高速度。让我们看看两种提问方式:
❌ 提示 1 (不具体): “重构上面的 getCombinedData 函数。”
AI 对提示 1 的响应:
当然。这是
getCombinedData的重构版本:
async function getCombinedData(apiClient) { // 并行获取用户和订单以提高性能 const [usersResponse, ordersResponse] = await Promise.all([ apiClient.fetch("/users"), apiClient.fetch("/orders"), ]); if (!usersResponse.ok || !ordersResponse.ok) { throw new Error("获取数据失败"); } const [users, orders] = await Promise.all([ usersResponse.json(), ordersResponse.json(), ]); // 按 userId 映射订单以便高效查找 const ordersByUser = {}; for (const order of orders) { if (!ordersByUser[order.userId]) { ordersByUser[order.userId] = []; } ordersByUser[order.userId].push(order); } // 合并数据 return users.map((user) => ({ user, orders: ordersByUser[user.id] || [], }));}我并行获取了用户和订单以提高性能。我还整合了错误处理,并使用了一个映射(ordersByUser)来按用户分组订单,这使得合并步骤更清晰,也可能更快。
分析: 这实际上是一个相当不错的重构,实现了几个改进:并行获取、为提高效率按用户分组订单、使用 .map 进行更清晰的数据合并并默认为空数组。AI 也解释了它做了什么。那么我们为什么把这个提示标记为不具体或“差”呢?在这种情况下,AI 碰巧做出了好的选择,但它假设了很多,因为提示是开放式的。它假设性能应该被提高(并行请求,这是一个聪明的改变,但如果在这里并行不安全呢?),并且它将错误处理改为一个通用的消息“获取数据失败”,这在合并错误时丢失了哪个调用失败的具体性。
使用一个泛泛的“重构这个”提示的风险在于,AI 可能会做出以意想不到的方式改变行为的修改。在这里,合并错误处理是否可接受,取决于需求。助手还做出了结构性改变(使用字典来分组订单)——这很好,可能更好,但如果我们有特定的约束(比如想要流式处理结果或保持低内存使用),我们没有告知它。所以虽然结果看起来不错,但 AI 对“重构”的自我解读与我们想要的相符,多少有些侥幸。这说明一个不具体的提示有时在简单情况下能得到好的结果,但对于复杂的代码,它可能会走向一个不希望的方向或错过你关心的一些改进。
✅ 提示 2 (目标导向): “重构上面的 getCombinedData 函数,以消除重复代码并提高性能。具体来说:(1) 避免为用户和订单重复获取逻辑——或许可以使用一个辅助函数或将它们一起获取。(2) 如果可能,并行获取两个列表。(3) 保留每次获取的错误处理(我们想知道哪个调用失败了)。(4) 改进数据合并,可能通过使用更高效的查找结构而不是嵌套循环。请提供重构后的代码,并附上解释更改的注释。”
AI 对提示 2 的响应:
当然!这是根据你要求的重构,改进后的
getCombinedData版本:
async function getCombinedData(apiClient) { // 1. 并行获取用户和订单以提高性能 const [usersResponse, ordersResponse] = await Promise.all([ apiClient.fetch("/users"), apiClient.fetch("/orders"), ]);
// 2. 分别处理错误,以便知道哪个调用失败了 if (!usersResponse.ok) { throw new Error("获取用户失败"); } if (!ordersResponse.ok) { throw new Error("获取订单失败"); }
// 并行解析 JSON 响应 const [users, orders] = await Promise.all([ usersResponse.json(), ordersResponse.json(), ]);
// 3. 使用一个按 userId 索引的查找映射,以便高效匹配订单 const ordersByUser = orders.reduce((map, order) => { if (!map[order.userId]) { map[order.userId] = []; } map[order.userId].push(order); return map; }, {});
// 4. 使用查找映射合并数据 return users.map((user) => ({ user, orders: ordersByUser[user.id] || [], // 如果用户没有订单,则为空数组 }));}更改说明:
- 并行获取: 我使用了
Promise.all来同时获取用户和订单(第 1 点)。- 保留了独立的错误处理: 我保留了对
usersResponse.ok和ordersResponse.ok的单独检查,这样任何错误都能清楚地指示哪个获取失败了(第 2 点)。- 并行 JSON 解析: 也对
response.json()调用使用了Promise.all,这是一个微小的改进。- 高效合并: 我没有使用嵌套循环,而是创建了一个
ordersByUser映射(第 3 点)。这在单次遍历中按userId对订单进行分组。然后我遍历用户来构建结果,以 O(1) 的时间复杂度从映射中拉取每个用户的订单(第 4 点)。这更高效、更简洁。*
分析: 这个响应直接解决了所有指定的目标。代码被重构得更清晰、更快,并且按照要求保留了独立的错误消息。AI 的解释确认了我们列出的每一点,这表明它仔细遵循了提示的指示。这是一个很好的结果,因为我们作为提问者,定义了在这种情况下“重构”意味着什么。通过这样做,我们引导 AI 产生一个符合我们需求的解决方案,且几乎不需要反复沟通。如果 AI 忽略了其中一点(比如说它仍然合并了错误处理),我们可以很容易地再次提问:“看起来不错,但请确保用户和订单的错误信息保持独立。”——然而,在这种情况下,这并不需要,因为我们的提示很详尽。
这个例子展示了一个关键的教训:当你知道你想要改进什么时,把它说清楚。 AI 擅长遵循指令,但它不会读心术。一个宽泛的“让这个更好”可能对简单的事情有效,但对于不那么琐碎的代码,通过列举“更好”对你意味着什么,你会得到最好的结果。这与社区的见解一致,即清晰、结构化的提示会显著改善结果。
额外的重构技巧:
-
分步重构: 如果代码非常庞大或者你有一长串的改动,你可以一次只处理一个。例如,先让 AI “为了可读性进行重构”(专注于重命名、拆分函数),然后再“优化这个函数中的算法”。这可以防止一次性给模型太多指令而使其不知所措,并让你逐步验证每个改动。
-
寻求替代方案: 也许 AI 的第一次重构可行,但你对不同的角度感到好奇。你可以问,“你能用另一种方式重构它吗,比如使用函数式编程风格(例如,用数组方法代替循环)?” 或者 “用递归代替迭代方法怎么样,只是为了比较一下?” 这样,你就可以评估不同的解决方案。这就像与同事头脑风暴多种重构方案。
-
结合重构和解释来学习模式: 我们已经提到过这一点,但值得强调——把 AI 当作一个学习工具。如果它用一种巧妙的方式重构了代码,研究其输出和解释。你可能会发现一种你以前没用过的新 API 或技巧(比如用
reduce构建一个映射)。这是要求解释的原因之一:它把一个答案变成了一个迷你教程,加深你对最佳实践的理解。 -
验证和测试: 在任何 AI 生成的重构之后,一定要运行你的测试或用示例输入来尝试代码。AI 可能会无意中引入细微的 bug,特别是如果提示没有指定一个重要的约束。例如,在我们的重构中,如果原始代码有意为日志记录而分离了获取错误,但我们没有提到日志记录,那么合并后的错误可能就没那么有用了。我们的工作是在审查中捕捉到这一点。AI 也可以帮助编写测试——你可以问*“为重构后的函数生成几个单元测试”*以确保它在预期输入上的行为与之前相同。
至此,我们已经涵盖了调试和重构——改进现有代码。合乎逻辑的下一步是使用 AI 辅助来实现新功能或生成新代码。我们将探讨如何有效地为该场景提问。
AI 代码助手最令人兴奋的用途之一是帮助你从头开始编写新代码,或将新功能集成到现有代码库中。这可以是从为 React 组件生成样板代码,到在 Express 应用中编写新的 API 端点。这里的挑战通常在于这些任务是开放式的——实现一个功能有很多种方法。为代码生成进行提示工程,就是引导 AI 产出符合你需求和风格的代码。以下是实现这一目标的策略:
1. 从高层指令开始,然后深入细节。 首先用通俗的语言概述你想构建什么,可以将其分解为更小的任务(类似于我们之前关于分解复杂任务的建议)。例如,假设你想在现有的 Web 应用中添加一个搜索栏功能。你可能首先提问:“概述一个计划,在我的 React 应用中添加一个搜索功能,该功能可以根据名称过滤产品列表。产品是从一个 API 获取的。”
AI 可能会给你一个分步计划:“1. 添加一个用于搜索查询的输入框。2. 添加状态来保存查询。3. 根据查询过滤产品列表。4. 确保搜索不区分大小写,等等。” 一旦你有了这个计划(你可以在 AI 的帮助下对其进行完善),你就可以用有针对性的提示来处理每个要点。
例如:“好的,实现第 1 步:创建一个 SearchBar 组件,带有一个输入框,用于更新 searchQuery 状态。” 之后,“实现第 3 步:给定 searchQuery 和一个产品数组,过滤产品(对名称进行不区分大小写的匹配)。” 通过分解功能,你确保每个提示都是具体的,响应也是可管理的。这也模仿了迭代开发——你可以在构建每个部分时对其进行测试。
2. 提供相关上下文或参考代码。 如果你正在向现有项目中添加功能,向 AI 展示该项目中类似功能是如何实现的会非常有帮助。例如,如果你已经有一个与你想要的相似的组件,你可以说:“这是一个现有的 UserList 组件(代码…)。现在创建一个 ProductList 组件,它类似但包含一个搜索栏。”
AI 会看到这些模式(也许你使用了某些库或风格约定)并应用它们。打开相关文件或在你的提示中引用它们,可以提供上下文,从而生成更符合项目特性和一致性的代码建议。另一个技巧是:如果你的项目使用特定的编码风格或架构(比如用 Redux 进行状态管理或某个 CSS 框架),请提及它。“我们使用 Redux 进行状态管理——请将搜索状态集成到 Redux store 中。”
一个训练有素的模型接着会生成符合 Redux 模式等的代码。本质上,你是在向 AI 传授你项目的环境,以便它能量身定制输出。一些助手甚至可以利用你的整个仓库作为上下文来借鉴;如果使用这些工具,请确保你将其指向你仓库中相似的模块或文档。
- 如果是开始新项目但你有偏好的方法,你也可以提及:“我希望使用函数式编程风格来实现这个(没有外部状态,使用数组方法)。” 或者,“确保遵循 MVC 模式,将逻辑放在控制器中,而不是视图中。” 这些是资深工程师可能会提醒初级工程师的细节,而在这里你是告诉 AI 的资深工程师。
3. 使用注释和 TODO 作为内联提示。 当直接在带有 Copilot 的 IDE 中工作时,一个有效的工作流程是写一条注释来描述你需要的下一块代码,然后让 AI 自动补全它。例如,在 Node.js 后端,你可能会写:// TODO: 验证请求负载(确保提供了 name 和 email),然后开始下一行。Copilot 通常会捕捉到意图并生成一个执行该验证的代码块。这是因为你的注释实际上是一个自然语言提示。然而,如果 AI 误解了,要准备好编辑生成的代码——一如既往,验证其正确性。
4. 提供预期输入/输出或用法的示例。 与我们之前讨论的类似,如果你要求 AI 实现一个新函数,请包含一个它将如何被使用的快速示例或一个简单的测试用例。例如:“在 JavaScript 中实现一个函数 formatPrice(amount),它接受一个数字(如 2.5)并返回一个格式化为美元的字符串(如 ‘$2.50’)。例如,formatPrice(2.5) 应该返回 ‘$2.50’。”
通过给出那个例子,你约束 AI 产出一个与之相符的函数。没有这个例子,AI 可能会假设其他一些格式或货币。差异可能很细微但很重要。在 Web 上下文中的另一个例子:“实现一个记录请求的 Express 中间件。例如,对 /users 的 GET 请求应该在控制台记录 ‘GET /users’。” 这清楚地说明了输出应该是什么样的。在提示中包含预期行为,就像一个 AI 会试图满足的测试。
5. 当结果不是你想要的,用更多细节或约束重写提示。 第一次尝试生成新功能时没有完全成功是很常见的。也许代码能运行但不够地道,或者它遗漏了一个需求。不要感到沮丧,把 AI 当作一个提交了初稿的初级开发者——现在你需要给出反馈。例如,“这个解决方案可行,但我更希望你使用内置的数组 filter 方法而不是 for 循环。” 或者,“你能把生成的组件重构为使用 React Hooks 进行状态管理而不是类组件吗?我们的代码库都是函数式组件。” 你也可以添加新的约束:“另外,确保函数在 O(n) 时间或更优的时间内运行,因为 n 可能很大。” 这种迭代式的提问非常强大。一个真实世界的场景:一个开发者让一个 LLM 生成代码来用一个 JS canvas 库画一个冰淇淋甜筒,但它一直给出不相关的输出,直到他们用更多具体细节和上下文优化了提示。教训是,不要一次尝试后就放弃。找出提示中缺少或被误解了什么,并加以澄清。这就是提示工程的精髓——每一次调整都能引导模型更接近你的设想。
让我们用一个示例场景来说明功能实现的提示过程:
假设我们有一个 React 应用,我们想添加一个新组件:一个带有搜索过滤器和排序下拉菜单的产品列表。这是一个 Web 应用中相当典型的功能。为简洁起见,我们将专注于提示该组件内的搜索功能。
初始提示(功能请求): “创建一个名为 ProductList 的 React 函数式组件,它显示一个产品列表,并包含一个文本输入框以按名称过滤产品。该组件应:从 /api/products 获取一个产品数组(假设它返回 {id, name, ...} 的 JSON 数组),将其存储在状态中,并允许用户在搜索框中输入以按名称过滤显示的产品(不区分大小写的匹配)。在一个简单的 <ul> 中显示过滤后的列表,并包含产品名称。包括基本的错误处理(例如,如果 API 调用失败则显示错误消息)和获取数据时的加载状态。”
这是一个很长的提示,但它很具体。让我们假设我们把这个交给一个聊天式 LLM。
AI 的响应(可能产生的内容摘要): AI 可能会输出一个类似这样的 ProductList 组件:
import React, { useState, useEffect } from "react";
function ProductList() { const [products, setProducts] = useState([]); const [search, setSearch] = useState(""); const [loading, setLoading] = useState(true); const [error, setError] = useState(null);
useEffect(() => { async function fetchProducts() { try { const res = await fetch("/api/products"); if (!res.ok) throw new Error("网络响应不正常"); const data = await res.json(); setProducts(data); } catch (err) { console.error("获取产品失败:", err); setError("加载产品失败。"); } finally { setLoading(false); } } fetchProducts(); }, []);
const handleSearchChange = (e) => { setSearch(e.target.value); };
// 根据搜索查询过滤产品(不区分大小写) const filteredProducts = products.filter((product) => product.name.toLowerCase().includes(search.toLowerCase()), );
if (loading) return <div>正在加载产品...</div>; if (error) return <div>{error}</div>;
return ( <div className="product-list"> <input type="text" placeholder="搜索产品" value={search} onChange={handleSearchChange} /> <ul> {filteredProducts.map((prod) => ( <li key={prod.id}>{prod.name}</li> ))} </ul> </div> );}
export default ProductList;(如果我们要了,代码中可能还会包含解释每个部分的注释。)
现在,让我们分析这个结果并考虑提示的优化:
-
假设返回了上面的代码,但我们的项目使用上下文或全局 store 进行数据获取,而不是在组件内部获取。这是我们没有指明的事情。AI 做出了在
useEffect中获取的选择。如果我们更喜欢使用自定义钩子或上下文,我们应该暗示这一点。所以我们可以优化我们的提示:“实际上,在我们的应用中,我们使用一个自定义钩子useProducts(),它已经处理了数据获取。请重构该组件以使用useProducts钩子,而不是直接调用fetch。” AI 接着会进行调整,可能会假设useProducts返回{ products, loading, error }并相应地简化组件。 -
另一个优化:也许我们意识到我们还想要一个排序下拉菜单(我们最初没有提到)。我们现在可以扩展对话:“很好,现在添加一个下拉菜单来按名称对产品进行排序(A-Z 或 Z-A)。下拉菜单应该让用户选择升序或降序,列表应该在过滤的基础上相应排序。” 因为 AI 有现有代码的上下文,它可以插入一个排序状态并调整渲染。我们提供了一个清晰的新需求,它会尝试满足,很可能会添加类似这样的东西:
const [sortOrder, setSortOrder] = useState("asc");// ... 一个用于 sortOrder 的 select 输入框 ...// 并在渲染前对 filteredProducts 进行排序:const sortedProducts = [...filteredProducts].sort((a, b) => { if (sortOrder === "asc") return a.name.localeCompare(b.name); else return b.name.localeCompare(a.name);});- (以及下拉菜单的 UI)。
通过这样逐个功能的迭代,我们与 AI 模拟了一个开发周期。这比试图一开始就用一个提示要求包含所有功能的整个复杂组件要有效得多。它减少了错误,并允许在需求变得更清晰时进行中途修正。
- 如果 AI 犯了一个细微的错误(比如它忘了让搜索过滤器不区分大小写),我们只需指出:“让搜索不区分大小写。” 它会调整过滤器以使用小写比较(在我们的伪输出中它已经这样做了,但如果没有,它会修复它)。
这个例子表明,用 AI 实现功能完全是关于增量开发和提示优化。一个 Twitter 帖子可能会惊叹某人如何通过不断为 LLM 提问每个部分来构建一个小应用——这本质上就是这种方法:构建、审查、优化、扩展。每个提示就像你开发过程中的一次提交。
额外的功能实现技巧:
-
让 AI 搭建骨架,然后你填充细节: 有时让 AI 生成一个粗略的结构,然后你再进行调整会很有用。例如,“为用户注册生成一个 Node.js Express 路由的骨架,包含验证和错误处理。” 它可能会产生一个带有占位符的通用路由。然后你可以填充特定于你应用的实际验证规则或数据库调用。AI 为你省去了编写样板代码的时间,而你则处理那些敏感的自定义逻辑。
-
要求处理边缘情况: 在生成一个功能时,你可能会提示 AI 思考边缘情况:“对于这个功能,我们应该考虑哪些边缘情况(你能在代码中处理它们吗)?” 例如,在搜索的例子中,一个边缘情况可能是“当用户输入时产品还未加载怎么办?”(尽管我们的代码通过加载状态处理了这一点)或者“如果两个产品同名怎么办”(不是大问题,但也许可以提一下)。AI 可能会提到诸如空结果处理、非常大的列表(可能需要对搜索输入进行防抖处理)等。这是一种利用 AI 对常见陷阱的训练数据的方式。
-
文档驱动开发: 一些人采取的一个巧妙方法是先写一个文档字符串或用法示例,然后让 AI 实现函数以匹配它。例如:
/** * 返回第 n 个斐波那契数。 * @param {number} n - 斐波那契数列中的位置(从 0 开始索引)。 * @returns {number} 第 n 个斐波那契数。 * * 示例: fibonacci(5) -> 5 (数列: 0,1,1,2,3,5,...) */function fibonacci(n) { // ... 实现}- 如果你写了上面的注释和函数签名,一个 LLM 可能会正确地填充实现,因为注释确切地描述了要做什么,甚至给出了一个例子。这个技巧确保你首先用语言澄清了功能(这通常是一个好习惯),然后 AI 用它作为规范来编写代码。
既然我们已经涵盖了调试、重构和新代码生成的提示策略,现在让我们把注意力转向在为编码进行提示工程时的一些常见陷阱和反模式。了解这些将帮助你避免在无成效的互动上浪费时间,并在 AI 没有给你想要的东西时迅速调整。
额外示例
❌ 差的提示: “我的 useEffect 不起作用”
✅ 增强的提示:
我有一个 React 组件用于获取用户数据,但它导致了无限次的重新渲染。这是我的代码:
const UserProfile = ({ userId }) => { const [user, setUser] = useState(null); const [loading, setLoading] = useState(true);
useEffect(() => { fetchUser(userId).then(setUser).finally(() => setLoading(false)); }, [userId, setUser, setLoading]); // 问题在这里
return loading ? <div>正在加载...</div> : <div>{user?.name}</div>;};预期行为: 当 userId 改变时,应该只获取一次用户数据。
实际行为: 组件无限次重新渲染。
控制台错误: “Warning: Maximum update depth exceeded”
是什么导致了这个无限循环,我该如何修复依赖数组?
为什么这有效: 提供了确切的代码、错误信息、预期与实际行为,并聚焦于一个通常被误解的特定 React 模式。
❌ 差的提示: “为我的 Next.js 电商应用构建状态管理”
✅ 增强的提示:
我正在构建一个 Next.js 14 的电商应用,需要设计状态管理架构。以下是我的需求:
组件:
- 产品列表页 (需要:
products[], 过滤器, 分页) - 购物车 (需要: 购物车项, 总计, 配送信息)
- 用户认证 (需要: 用户资料, 认证状态, 偏好设置)
- 实时通知 (需要: toast 消息, 错误状态)
技术约束:
- Next.js 14,使用 App Router 和 Server Components
- TypeScript 严格模式
- 为 SEO 进行服务器端数据获取
- 购物车/用户操作的客户端交互性
- 状态应在导航之间持久化
我应该使用:
- 为每个领域(购物车、认证、通知)使用 Zustand stores
- React Query/TanStack Query 用于服务器状态 + Zustand 用于客户端状态
- 一个带有切片(slices)的单一 Zustand store
请提供一个推荐的架构,并附上代码示例,展示如何构建 stores 并与 Next.js App Router 模式集成。
为什么这有效: 这是一个包含特定技术栈、清晰需求,并要求提供架构指导和实现细节的真实世界场景。
并非所有的提示都是生而平等的。到目前为止,我们已经看到了许多有效提示的例子,但认识到反模式——那些导致 AI 响应不佳的常见错误——也同样具有启发性。

这里有一些常见的提示失败案例以及如何修复它们:
-
反模式:模糊的提示。 这是经典的*“它不工作,请修复它”或“写一个能做 X 的东西”而没有足够细节的例子。我们之前看到过一个例子,当问题“为什么我的函数不工作?”得到一个无用的答案时。模糊的提示迫使 AI 猜测上下文,通常导致泛泛的建议或不相关的代码。解决方法很简单:添加上下文和具体细节。如果你发现自己问了一个问题,而答案感觉像一个魔力 8 号球的回应(“你试过检查 X 吗?”),停下来,用更多细节(错误信息、代码摘录、预期与实际结果等)重新组织你的查询。一个好的做法是读一下你的提示,然后问自己,“这个问题能适用于几十种不同的场景吗?”* 如果是,那它就太模糊了。让它变得具体,以至于它只能适用于你的场景。
-
反模式:超载的提示。 这是相反的问题:一次性要求 AI 做太多的事情。例如,“生成一个完整的 Node.js 应用,包含认证、React 前端和部署脚本。” 或者在更小的规模上,“一次性修复这 5 个 bug 并添加这 3 个功能。” AI 可能会尝试,但你很可能会得到一个混乱或不完整的结果,或者它可能会忽略请求的某些部分。即使它处理了所有事情,响应也会很长,难以验证。解决方法是分解任务。排定优先级:一次只做一件事,正如我们之前强调的。这使得捕捉错误更容易,并确保模型保持专注。如果你发现自己写的段落中包含多个“和”的指令,考虑把它分解成单独的提示或顺序步骤。
-
反模式:缺失问题。 有时用户会提供大量信息,但从未清楚地提问或指明他们需要什么。例如,扔下一大段代码片段,只说“这是我的代码”。这会使 AI 感到困惑——它不知道你想要什么。总是包含一个明确的要求,比如*“识别上述代码中的任何 bug”、“解释这段代码做什么”或“完成代码中的 TODO。”* 一个提示应该有一个目的。如果你只提供文本而没有问题或指令,AI 可能会做出错误的假设(比如总结代码而不是修复它等)。确保 AI 知道你为什么给它看一些代码。即使是简单的补充,如*“这段代码有什么问题?”或“请继续实现这个函数。”*也能给它方向。
-
反模式:模糊的成功标准。 这是一个微妙的问题——有时你可能会要求优化或改进,但你没有定义成功的标准是什么。例如,“让这个函数更快。” 按什么标准更快?如果 AI 不知道你的性能限制,它可能会微观优化一些无关紧要的东西,或者使用一种理论上更快但实际上可以忽略不计的方法。或者*“让这段代码更整洁”*——“整洁”是主观的。我们通过明确说明目标,如“减少重复”或“改进变量名”等来处理这个问题。解决方法是:量化或限定改进。例如,“优化这个函数,使其以线性时间运行(当前版本是二次的)”或“重构这个,移除全局变量,改用一个类。” 基本上,明确说明你正在通过重构或功能解决什么问题。如果你把它留得太开放,AI 可能会解决一个与你关心的问题不同的问题。
-
反模式:忽略 AI 的澄清或输出。 有时 AI 可能会用一个澄清性问题或一个假设来回应。例如:“你用的是 React 类组件还是函数式组件?”或“我假设输入是一个字符串——请确认。” 如果你忽略这些,只是重申你的请求,你就错失了一个改进提示的机会。AI 在示意它需要更多信息。总是回答它的问题或优化你的提示以包含那些细节。此外,如果 AI 的输出明显错误(比如它误解了问题),不要只是逐字重复相同的提示。花点时间调整你的措辞。也许你的提示有一个模棱两可的短语或遗漏了某些必要的东西。把它当作一次对话——如果一个人误解了,你会用不同的方式解释;对 AI 也一样。
-
反模式:风格多变或不一致。 如果你不断改变提问方式或在一次提问中混合不同的格式,模型可能会感到困惑。例如,在指令中在第一人称和第三人称之间切换,或者用一种令人困惑的方式混合伪代码和实际代码。尝试在单个提示中保持一致的风格。如果你提供例子,确保它们被清晰地划分(使用 Markdown 的三反引号表示代码,引号表示输入/输出示例等)。一致性帮助模型正确解析你的意图。另外,如果你有偏好的风格(比如 ES6 vs ES5 语法),要始终如一地提及它,否则模型可能会在一个提示中建议一种方式,在稍后的提示中又建议另一种。
-
反模式:像“上面的代码”这样的模糊引用。 在使用聊天时,如果你说“上面的函数”或“之前的输出”,要确保引用是清晰的。如果对话很长,你说“重构上面的代码”,AI 可能会跟丢或选择错误的代码片段进行重构。更安全的方法是再次引用代码或明确指出你想要重构的函数名。模型有一个有限的注意力窗口,尽管许多 LLM 可以引用对话的先前部分,但再次给它明确的上下文可以帮助避免混淆。如果代码显示后过了一段时间(或几条消息),这一点尤其正确。
最后,这里是一个在事情出错时重写提示的战术方法:
-
识别 AI 响应中缺少或不正确的地方。 它是否解决了不同的问题?它是否产生了错误或一个不合适的解决方案?例如,也许你要求一个 TypeScript 的解决方案,但它给了纯 JavaScript。或者它写了一个递归的解决方案,而你明确想要迭代的。找出差异。
-
在一个新的提示中添加或强调那个要求。 你可以说,“解决方案应该是 TypeScript,而不是 JavaScript。请包含类型注解。” 或者,“我提到我想要一个迭代的解决方案——请避免递归,改用循环。” 有时在你的提示中使用像*“注意:”或“重要:”这样的短语来强调关键约束会有帮助(模型没有情感,但它确实会把某些措辞看作是重要性的标志)。例如:“重要: 不要为此使用任何外部库。”* 或 “注意: 代码必须在浏览器中运行,所以不要使用 Node 特有的 API。”。
-
如果需要,进一步分解请求。 如果 AI 在一个复杂的请求上反复失败,试着先要求一个小一点的部分。或者问一个可能有助于阐明情况的问题:“你理解我说的 X 是什么意思吗?” 模型然后可能会复述它认为你的意思,如果它错了你可以纠正它。这是元提示(meta-prompting)——讨论提示本身——有时可以解决误解。
-
如果对话卡住了,考虑重新开始。 有时在多次尝试后,对话可能会进入一个混乱的状态。开始一个新的会话(或暂时清除聊天记录)并用你根据之前的失败制定的更精确的请求从头开始提问会有帮助。模型不介意重复,一个全新的上下文可以消除先前消息中积累的任何困惑。
通过意识到这些反模式及其解决方案,你将能更快地即时调整你的提示。对于开发者来说,提示工程在很大程度上是一个迭代的、反馈驱动的过程(就像任何编程任务一样!)。好消息是,你现在工具箱里已经有很多模式和例子可以借鉴了。
提示工程既是一门艺术,也是一门科学——正如我们所见,它正迅速成为使用 AI 代码助手的开发者必备的技能。通过精心制作清晰、富含上下文的提示,你实际上是在教导 AI 你需要什么,就像你引导一个新团队成员或向同事解释一个问题一样。在本文中,我们探讨了如何系统地处理用于调试、重构和功能实现的提示:
-
我们学会了向 AI 提供与向同事求助时相同的信息:代码应该做什么、它如何出问题、相关的代码片段等等——从而获得更有针对性的帮助。
-
我们看到了与 AI 迭代的威力,无论是逐行审视函数逻辑,还是通过多个提示优化解决方案(比如将递归方案改为迭代方案,然后改进变量名)。耐心和迭代将 AI 变成了真正的结对程序员,而不是一次性的代码生成器。
-
我们利用角色扮演和身份来提升响应的水平——将 AI 视为代码审查员、导师或某个技术栈的专家。这通常会产生更严谨、解释更丰富的输出,不仅解决了问题,还在过程中教育了我们。
-
对于重构和优化,我们强调了定义“好”的标准(无论是更快、更清晰、更地道等),而 AI 也展示了在被引导时它能应用已知的最佳实践(如并行化调用、消除重复、正确处理错误)。这就像可以接触到无数代码审查员的集体智慧——但你必须问对问题才能利用它。
-
我们还演示了在 AI 的协助下逐步构建新功能,表明即使是复杂的任务也可以被分解并一次一个提示地解决。如果被提示,AI 可以搭建样板代码、建议实现方案,甚至指出边缘情况——扮演一个知识渊博、随时待命的合作开发者。
-
在此过程中,我们识别了要避免的陷阱:保持提示既不太模糊也不太超载,始终明确我们的意图和约束,并准备在 AI 的输出不达标时进行调整。我们引用了不良提示的具体例子,并看到了微小的改变(如包含错误信息或预期输出)如何能极大地改善结果。
当你将这些技巧融入你的工作流程时,你可能会发现与 AI 的合作变得更加直观。你会对什么样的措辞能得到最好的结果,以及当模型偏离轨道时如何引导它产生一种感觉。请记住,AI 是其训练数据的产物——它看过许多代码和解决问题的例子,但提供方向,指明哪些例子现在是相关的,是你的工作。本质上,你设定上下文,AI 跟进。
同样值得注意的是,提示工程是一门不断发展的实践。 开发者社区在不断发现新的技巧——一个巧妙的一行提示或一个结构化的模板可能会突然在社交媒体上走红,因为它解锁了人们没意识到的能力。请关注那些讨论(在 Hacker News、Twitter 等),因为它们可以启发你自己的技巧。但也不要害怕自己去实验。把 AI 当作一个灵活的工具——如果你有一个想法(“如果我让它画出我的架构的 ASCII 图会怎么样?”),就试试看。你可能会对结果感到惊讶,如果失败了,也没什么损失——你对模型的局限性或需求有了新的了解。
总之,提示工程使开发者能够从 AI 助手中获得更多。 这是“这工具没用,给了我一堆胡说八道”的挫败体验和“这感觉就像和一个为我写样板代码的专家结对编程”的高效体验之间的区别。通过应用我们所涵盖的策略手册——从提供详尽的上下文到调整 AI 的风格和思维——你可以将这些专注于代码的 AI 工具变成你开发工作流程的真正延伸。最终结果不仅是你编码更快,而且你常常在此过程中学到新的见解和模式(当 AI 解释事情或建议替代方案时),从而提升你自己的技能水平。
作为最后的总结,请记住提示是一个迭代的对话。以你与另一位工程师沟通时所使用的同样清晰、耐心和彻底的态度来对待它。做到这一点,你会发现 AI 助手可以极大地增强你的能力——帮助你更快地调试、更聪明地重构,并更轻松地实现功能。
祝你提示愉快,编码快乐!
进一步阅读: